The Enterprise Guide to Autonomous AI Agents (Strategy, Architecture, Security, and Rollout)

autonomous ai agents are moving from demos to real business workflows and if you’re leading a team that’s being asked to “do something with ai agents” but aren’t sure where to start, this is your roadmap
the hype is loud but the reality is simpler than it sounds. agents can plan multi-step tasks, use tools to interact with your systems, adapt when conditions change, and remember context across interactions. they’re not chatbots that just respond and they’re not rpa that follows rigid scripts. agents reason through ambiguity and figure out what to do next based on the goal you gave them
most enterprise deployments use human-in-the-loop approval gates where the agent proposes an action and waits for confirmation before executing anything risky. the agent still does the reasoning and prep work—you just control when it happens. autonomy doesn’t mean zero oversight
this guide walks through what agents actually are, why they matter now, how to pick the right use cases, what the production stack looks like, how to manage risk and governance, and how to avoid the mistakes that kill most projects before they ship. this isn’t theory—it’s what works in real enterprise deployments where security matters, budgets are scrutinized, and failure has consequences
where to start: enterprise ai agent strategy
prioritizing use cases that actually matter
most agent projects fail because teams skip strategy and jump straight to vendor demos. they pick a platform, spin up a proof-of-concept, realize they don’t know what success looks like, and the project stalls
the first question isn’t “which platform should we use”—it’s “which workflows are expensive, repetitive, and annoying enough that automating them would actually matter”. look for workflows where volume is high, inputs vary, manual effort is expensive, cycle time matters, and errors are costly
common high-value targets: itsm ticket resolution, customer support triage, invoice processing, finance reconciliation, sales ops workflows. these hit the sweet spot of high volume, variable inputs, and measurable roi
defining success metrics before you build
vague goals like “improve efficiency” will kill your project. you need metrics that finance and operations will actually track: ticket deflection rate, avg cost per ticket, cycle time reduction, error rate improvement, escalation rate
pick 2-3 metrics max for your first deployment. track them weekly. if you’re not seeing movement in 90 days, either the use case was wrong or the implementation needs serious tuning
setting realistic scope
don’t try to automate everything at once. good first deployment: one workflow (password resets, not “all of itsm”), one team or business unit, 3-6 month timeline, human-in-the-loop for high-risk actions, clear success criteria
start narrow. prove value. expand scope once you’ve validated the approach and worked out the operational kinks

building the stack: enterprise ai agent architecture
core components every agent system needs
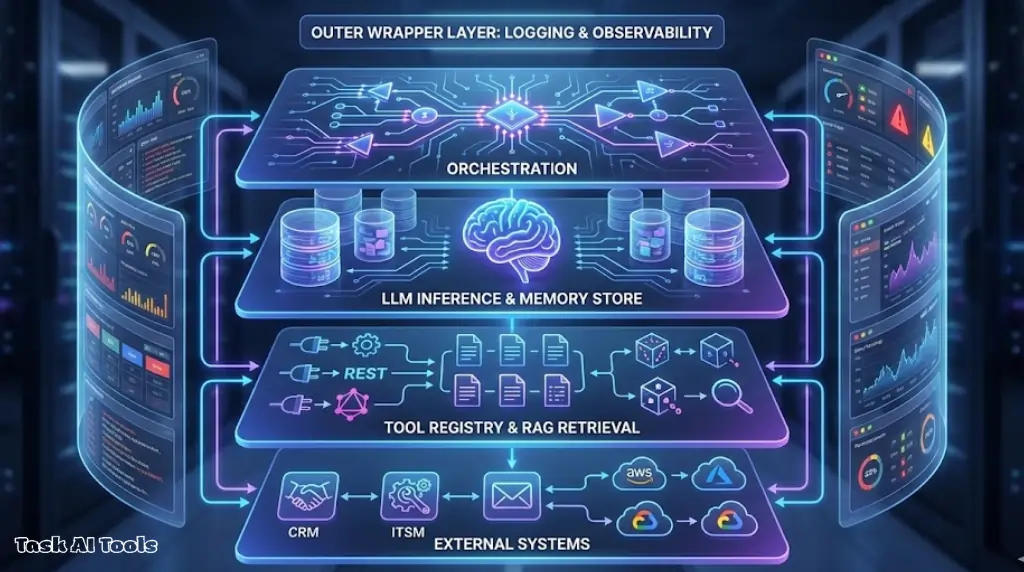
demos show the happy path but production systems need more. every agent needs an orchestration layer (manages the agent loop), llm inference (the reasoning engine), a tool registry (catalog of available functions), retrieval layer for rag (queries your knowledge base), and memory stores (tracks context)
the orchestration layer receives tasks, plans steps, calls tools, evaluates results, and adapts or escalates. llm inference can be hosted apis like openai or anthropic, or self-hosted models depending on data residency requirements. tools need clear schemas so the llm knows when and how to use them. rag lets agents query documents without memorizing everything
production requirements that demos skip
the real work is in observability, error handling, security controls, and cost management. you need to log every step so you can debug failures. track success rate, tool accuracy, response quality, and cost per task. implement circuit breakers that halt after consecutive failures, retry logic with exponential backoff, and rollback mechanisms for destructive actions
security means least-privilege tooling—agents get scoped api keys not admin credentials. rotate secrets regularly and audit access logs. cost controls include caching identical queries, optimizing prompt length, and setting rate limits so spend doesn’t spike unexpectedly
key design decisions and tradeoffs
api hosting is faster to deploy but self-hosted gives you data residency control. frameworks like langgraph are quick to start but custom code gives full control. stateless context works for simple tasks but stateful memory is needed for multi-turn workflows. high-risk actions need human approval, low-risk can use automated validation
managing risk: security and governance for ai agents
the five failure modes that matter
autonomy changes the risk profile because agents can act, not just respond. the failures that hurt: hallucinations where agents fabricate facts, data leakage exposing sensitive info to wrong users, tool misuse calling wrong apis or passing bad parameters, runaway loops where agents get stuck retrying forever, and lack of auditability where you can’t trace what happened or why
these aren’t theoretical—they happen in production if you don’t design safeguards upfront. the good news is mitigation is straightforward if you build it in from day one
implementing controls that reduce blast radius
use rag to ground responses in verified sources instead of letting the model guess. enforce least-privilege access at the tool level—agents should only query systems they need for the specific task, using scoped credentials not admin keys. set max iteration limits and timeouts to prevent infinite loops. log every step immutably so you can reconstruct decisions later
tier actions by risk: low-risk like read-only queries run autonomously with basic logging. medium-risk like drafting emails wait for human review. high-risk like sending external comms or updating financial records require explicit approval plus full audit trails plus rollback options
governance policies and approval flows
before you deploy, document which workflows the agent handles, which systems it accesses, which actions require approval, how long data is retained, who can override decisions, and what happens when failures occur. then enforce with technical controls: rate limits, input validation, output filtering, circuit breakers
security teams will ask about data residency, access controls, audit trails, failure modes, and regulatory compliance. have clear answers ready or the project gets blocked late

proven deployments: top enterprise use cases
itsm and it operations workflows
tier-1 ticket resolution is the sweet spot—password resets, account unlocks, software access requests, basic troubleshooting. agents can handle 40-60% of tier-1 volume if you give them access to identity systems, knowledge bases, and ticketing apis. what good looks like: agent reads ticket, checks user permissions, follows runbook, proposes fix, waits for approval if high-risk, executes and closes ticket. deflection rate hits 50%+ within 90 days
incident triage and routing is another high-value target. agents read incoming alerts, pull context from monitoring systems, search runbooks for similar incidents, and route to the right team with a diagnostic summary. this cuts mean-time-to-acknowledge by 30-40% and reduces noise for on-call engineers
customer support and finance automation
for customer support, agents handle billing questions, order status, account updates—the repetitive stuff so humans focus on complex or emotional issues. agents that deflect 40-50% of inbound volume while maintaining or improving customer satisfaction are considered successful. the key is clear escalation paths and handing off with full context
in finance, invoice processing is proven—agents read invoices even when formats vary, extract line items, match against purchase orders, flag discrepancies, and route for approval. processing time drops from days to hours with error rates below 2%. expense report review works similarly: check submissions against policy, flag violations, auto-approve compliant reports
choosing platforms: evaluation checklist and vendor selection
what to assess before vendor demos
platform selection is where time gets wasted because teams compare features that don’t matter or miss requirements that’ll block deployment later. start with integrations—map which tools the agent needs to connect to: crm, itsm, identity systems, databases, communication tools, internal apis. check if the platform has pre-built connectors or if you’ll build custom integrations from scratch
security and access controls come next. can the platform enforce least-privilege access, support scoped api keys, provide audit logging? where does data live—on-premises, in your vpc, or vendor’s cloud? is it encrypted at rest and in transit? does it meet your compliance requirements like soc2, gdpr, hipaa? if your security team can’t sign off on the architecture, the project dies
observability matters more than most teams realize. when the agent makes a mistake, can you see why? does the platform log every step—task received, plan generated, tools called, outputs returned, errors encountered? can you replay sessions to debug failures? are logs searchable and exportable?
the rfp questions that expose gaps
skip the fluff about company vision. ask: which systems do you integrate with out of the box? how long does it take to add a custom integration? where does agent data live and can we control data residency? how are credentials managed? what logging and monitoring do you provide? what’s your pricing model and what’s the cost difference between pilot and production scale? can we use our own llm or are we locked into yours?
red flags that should disqualify vendors: no audit logs or observability, vague security answers, locked-in llm with no flexibility, no support for approval gates or human-in-the-loop, unclear pricing or hidden costs

final considerations
what separates successful deployments from stalled projects
the teams that ship agents successfully do a few things right: they pick workflows with clear roi, they design controls that match the risk profile, they involve security and compliance early, they start narrow and expand after proving value, and they measure outcomes that finance will believe
the teams that stall pick vague use cases, skip governance, ignore integration complexity, overscope the first deployment, or can’t explain what success looks like. agents aren’t magic—they’re systems that need strategy, architecture, and operational discipline
key success factors summary
| factor | what works | what kills projects |
|---|---|---|
| use case selection | high-volume, variable inputs, measurable roi | vague scope, low value, unpredictable outcomes |
| metrics | 2-3 clear kpis tracked weekly | “productivity gains” with no numbers |
| scope | one workflow, one team, 3-6 months | “automate everything”, no boundaries |
| governance | risk-tiered approvals, audit trails | no controls or fully autonomous with no oversight |
| stakeholders | security and finance involved early | technical team working in isolation |
| iteration | budget for tuning and learning | one-shot launch with no room to adapt |
autonomous agents are real. the hype will fade but the capability will stay. the question is whether your team figures it out before your competitors do. start with strategy, build the right architecture, implement proper controls, prove value in a narrow scope, then expand deliberately.